
С чего начать, чтобы понять ИИ по-настоящему
Откуда берётся то, что отвечает в ChatGPT. Кто придумал. Какие уравнения внутри.
Я физик-теоретик и художник. Занимался космологией и квантовой механикой, а потом построил компанию по внедрению ИИ в бизнес. Нейросеть — это прикладная математика, которую человечество собирало тысячелетиями.
В этой серии мы пройдём путь от камня до нейронки. Будем складывать замок из простых кубиков: сначала арифметика как в первом классе, потом — чуть сложнее, и в конце вы увидите, как из этих кубиков получается то, что отвечает вам в ChatGPT.
Цель — не сделать из вас ML-инженеров. Цель — чтобы вы понимали что происходит внутри и видели, где в вашем бизнесе реально есть деньги.
ИИ — это старая математика, которой наконец-то хватило вычислительной мощи. Понять как она устроена — значит видеть, где реально есть деньги.
Всё началось гораздо раньше
Задолго до компьютеров. До бумаги. До письменности. Вот как эти кубики складывались тысячелетиями — и что происходило в мире одновременно с каждым из них.
Малоберцовая кость бабуина с 29 насечками. Найдена в пещере Border Cave в горах Лебомбо (Свазиленд/эСватини). 24 радиоуглеродные датировки подтверждают возраст 42 000–43 000 лет. Вероятно — лунный календарь или счётная палочка. Это самый первый кубик.

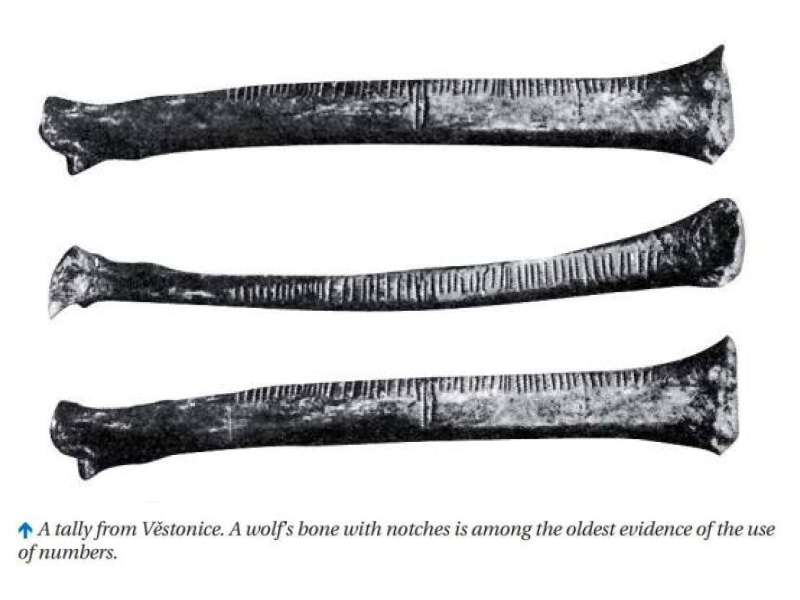
Кость волка с 55 насечками, разделёнными на группы. Найдена в Долни Вестонице (Чехия) в 1937 году. Насечки сгруппированы по пять — возможно, первое свидетельство счёта по пальцам руки (пятеричная система). Первый намёк на систему.

Кость Ишанго, найдена в Конго. 168 насечек в трёх рядах. Люди считали дни, фазы луны, животных. Это самый первый кубик — само понятие «больше» и «меньше», записанное руками.


Шумеры придумали позиционную запись: можно записать не только «три», но и «три тысячи». Египтяне считали площадь полей после разливов Нила. Числа стали инструментом управления государством.

Вавилонская глиняная табличка Плимптон 322 — таблица пифагоровых троек (числа для прямоугольных треугольников: a²+b²=c²). По исследованиям UNSW — вероятно древнейшая тригонометрическая таблица. За 1 600 лет до Пифагора.

Пифагор и Евклид. Квадрат гипотенузы равен сумме квадратов катетов. На шаге 3 этой серии мы увидим: именно эта формула работает внутри ChatGPT — только в 768 измерениях вместо двух.

аль-Хорезми в Багдаде. Слово «алгебра» — из его книги. Слово «алгоритм» — от его имени. Работа с неизвестными: x, уравнения, систематический метод решения. Этот подход лежит в основе любого кода.

Ньютон и Лейбниц независимо. Производная — скорость изменения в точке. Именно этот инструмент стоит в основе обучения нейросети: градиентный спуск работает на производных. Через 350 лет это будет обучать GPT.

y=f(Σwx+b)
активация
обучение
внимание
слов
Пифагора
число
алгебра
анализ
вероятностей
на кости
запись
и x
d/dx
вер.
Разные люди, в разных странах, в разные века — каждый решал свою задачу. Никто не знал, что строит часть будущего ИИ.





